แนะนำ Kafka สำหรับ data integration
Kafka คืออะไร?
Apache Kafka เป็นระบบกระจายข้อความ(message, event, log, ฯลฯ) ที่ถูกออกแบบให้เป็นศูนย์กลางของการส่งข้อความในองค์กรขนาดใหญ่ ที่ถูกพัฒนาโดย LinkedIn และปัจจุบันเป็นซอฟท์แวร์เสรี (open source)
Kafka ถูกออกแบบมาให้เร็ว, ปรับขยายได้ง่าย, มีความคงทนของข้อมูล, มี High Availability (ทำงานกันเป็น cluster ไม่ล่มง่ายๆ), และสามารถทำ Disaser Recovery ได้
ลำดับขั้นความต้องการของ มาสโลว์ ข้อมูล
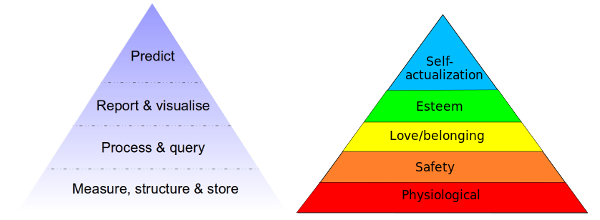
หากลองเปรียบเทียบลำดับขั้นความต้องการข้อมูล กับ ลำดับขั้นความต้องการของมาสโลว์ จะเห็นว่าการเตรียมข้อมูล และความต้องการทางกายภาพ นั้นอยู่ที่ฐานของพีระมิด ซึ่งถ้าเทียบกับคนแล้ว เราจะไม่สามารถทำอะไรต่อได้เลย หากไม่มีข้อมูลจากฐานของพีระมิด
การเตรียม/จัดการข้อมูลเป็นขั้นตอนที่ใช้เวลามาก บางครั้งอาจจะมากกว่าการนำข้อมูลไปใช้งานเสียอีก นี่คือปัญหาที่ LinkedIn พบและเป็นจุดเริ่มต้นให้มีการพัฒนา Kafka ขึ้นมาใช้ภายใน และใช้ช่วยเพิ่มประสิทธิภาพในการจัดการข้อมูลได้ในที่สุด
Jay Kreps (หนึ่งในผู้พัฒนา Kafka) บอกว่า ก่อนที่จะมี Kafka LinkedIn ต้องมีวิศวกรหลายคนที่ดูแลเรื่อง data integration โดยเฉพาะ แต่หลังจากมี Kafka แล้ว ไม่จำเป็นต้องมีวิศวกรที่ดูแลเรื่องนี้โดยตรงแบบเต็มเวลาอีกเลย
ตัวอย่าง data pipeline architecture ก่อน และหลัง Kafka
ตัวอย่างนี้เป็นตัวอย่าง data pipeline ของเวบแห่งหนึ่ง โดยมีโจทย์ว่า event ต่างๆที่เกิดจากผู้ใช้(click stream) จะต้องถูกประมวลผลด้วยระบบต่างๆในองค์กรเพื่อจุดประสงค์ที่ต่างกัน
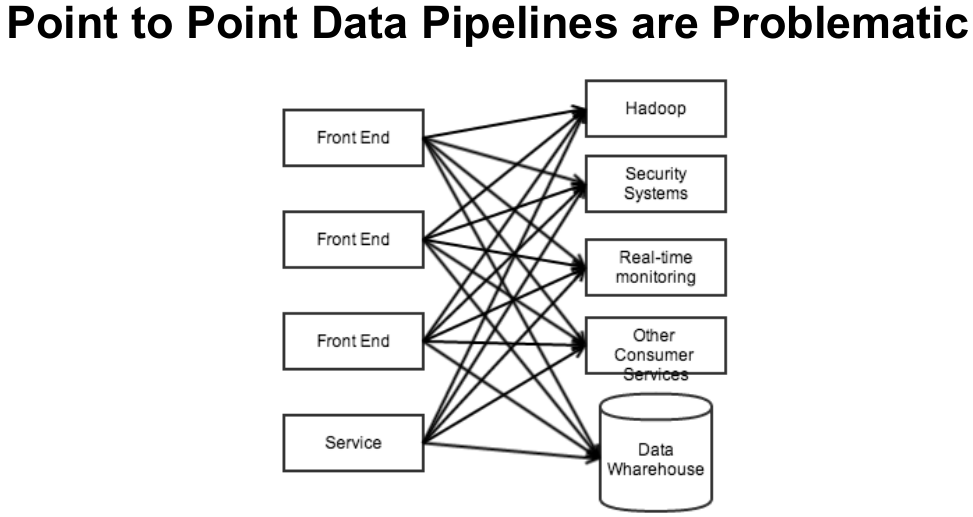
ตัวอย่างของ data pipeline แบบ point-to-point
Event : user กด like หน้าเพจ
- Front End –> Hadoop เพื่อทำ analytics/machine learning
- Front End –> Real-time monitoring เพื่อส่งขึ้น dashboard ของเจ้าของเพจ
- Front End –> Security Systems เพื่อตรวจสอบว่าเป็นการใช้ robot กด like หรือเปล่า
- Front End –> Other Consumer Service เพื่อเตือนไปยัง mobile app ของเจ้าของเพจ
- Front End –> Data Warehouse
จากตัวอย่างข้างบน Front End จะต้องรู้ว่า event ต่างๆที่เกิดขึ้น จะต้องส่งให้ service ใดบ้าง และส่งอย่างไร การดูแลรักษา และพัฒนาระบบที่ใช้ pipeline แบบนี้จะยาก และมีโอกาสผิดพลาดมากขึ้น ตามความซับซ้อนของระบบ
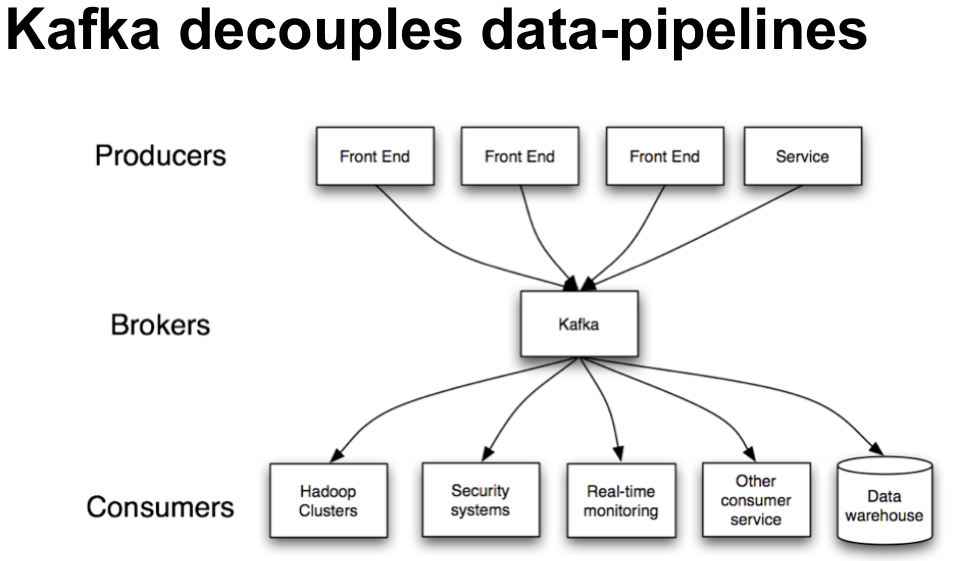
และนี่คือตัวอย่างของ data pipeline ที่ถูก decouple ด้วย Kafka
Event : user กด like หน้าเพจ
- Front End –> Kafka
- Kafka –> Hadoop
- Kafka –> Real-time monitoring
- Kafka –> Security Systems
- Kafka –> Other Consumer Service
- Kafka –> Data Warehouse
จากตัวอย่างนี้ Front End มีหน้าที่เดียวคือส่ง event ต่างๆที่เกิดขึ้นเข้า Kafka, และ service ต่างๆก็จะต้องรู้วิธีการอ่าน event ที่เกี่ยวข้องจาก Kafka เพื่อนำไปประมวลผลต่อตาม business logic ที่กำหนดไว้ ดังนั้นทีมที่ดูแล Front End และ service ต่างๆ สามารถทำงานแยกจากกัน และมีอิสระที่จะปรับเปลี่ยนระบบของตนเองได้ ขอเพียงแค่ส่งขอความหากันผ่าน Kafka ได้
สรุป
Kafka เป็น messaging system ที่รองรับข้อมูลที่มีความเร็ว และปริมาณมากได้
Kafka สามารถนำมาเป็นเครื่องมือในการเพิ่มประสิทธิภาพ และลดความซับซ้อนของ data pipeline(s) ในระบบขององค์กร
แม้ Kafka จะเป็นซอฟท์แวร์เสรี แต่ก็เป็นซอฟท์แวร์ที่พัฒนาและใช้งานจริงโดยองค์กรขนาดใหญ่อย่าง LinkedIn นอกจากนี้เวบชั้นนำต่างๆเช่น Yahoo, Twitter, Netflix, Uber, Paypal, Airbnb, ฯลฯ ก็ยังเลือกใช้ Kafka ในส่วนต่างๆของ backend ด้วย
Kafka จึงเป็นเครื่องมือหนึ่ง ที่น่านำมาพิจารณาใช้ เพื่อตอบสนอง ลำดับขั้นความต้องการข้อมูล ของคุณ