Spark เพื่อ data warehouse offload (ตอนที่ 2:incremental data load)
จากบทความตอนที่ 1 เราได้เห็นตัวอย่างของการดึงข้อมูลทั้ง table มาเก็บไว้ใน parquet file และ metastore สำหรับ Spark แล้ว ในตอนที่ 2 ผู้เขียนจะยกตัวอย่างกรณีที่ต้องการจะเพิ่มข้อมูลเข้าไปใน table จากตอนที่แล้ว
Append
ถ้าหากข้อมูลต้นทางมีแต่การเพิ่มจำนวน records โดยที่ไม่มีการแก้ไข หรือลบข้อมูล วิธีการเพิ่มข้อมูลใหม่ต่อจาก parquet file เก่าที่มีนั้นทำได้ง่ายมาก
เช่น
val fuelSales = spark.read.jdbc(mysqlUrl, targetTable, prop).where("year = 2016 and month = 9")
fuelSales.write.format("parquet").mode("append").saveAsTable("sparkFuelSalesTable")
spark.sql("select count(1) from sparkFuelSalesTable").show
+--------+
|count(1)|
+--------+
| 12782|
+--------+
เมื่อข้อมูลของเดือนใหม่มาครบ ( 2016-09 ) เราก็สามารถดึงข้อมูลเฉพาะของเดือนใหม่จาก data source เข้ามาเพิ่มต่อจากไฟล์ parquet เก่าได้โดยการเขียนด้วย append mode
การ append parquet file นั้นไม่ได้มีความซับซ้อนอะไรเลย มันเป็นเพียงการเพิ่ม parquet file ใหม่เข้าไปใน directory เท่านั้นเอง

และหากมีการ append ข้อมูลทุกเดือน ในหนึ่งปีก็จะมีไฟล์ 12 ไฟล์ หากไฟล์เล็กๆพวกนี้มีมากเกินไป เราสามารถยุบไฟล์พวกนี้รวมกันเป็นไฟล์เดียว (หรือจำนวนอื่นๆ) เพื่อช่วยให้ Spark ทำงานได้มีประสิทธิภาพมากขึ้นได้ด้วยคำสั่ง coalesce
val tableDF = spark.read.parquet("spark-warehouse/sparkfuelsalestable")
val newTableDF = tableDF.coalesce(1)
fuelSales.write.format("parquet").saveAsTable("sparkFuelSalesTableNew")

.coalesce(n) คือการลดข้อมูลให้เหลือ n partition โดยปกติแล้ว เราไม่ควรลดให้เหลือเพียง partition เดียว หากต้องการให้ทั้ง cluster ช่วยกัน process table นี้ได้อย่างมีประสิทธิภาพ ควรให้ n >= [number of Spark nodes]
และเมื่อสร้าง table ใหม่ที่ compact parquet files เรียบร้อยแล้วจึง drop table เก่าทิ้ง แล้ว rename table ใหม่
spark.sql("DROP TABLE sparkFuelSalesTable")
spark.sql("ALTER TABLE sparkFuelSalesTableNew RENAME TO sparkFuelSalesTable")
Predicate / filter pushdown
จากตัวอย่างการ append สิ่งที่ผู้เขียนอยากจะชี้ให้เห็นก็คือ Spark SQL รองสามารถทำ predicate pushdown / filter pushdownได้หาก data source รองรับ
Predicate pushdown / filter pushdown คือการสั่งให้ data source กรองข้อมูลตามที่ต้องการก่อน แล้วจึงส่งเฉพาะข้อมูลที่ต้องการกลับมาให้ Spark SQL การ pushdown where filter แบบนี้จะช่วยให้ Spark ทำงานได้เร็วขึ้น และลด load บน data source
Predicate pushdown รองรับ WHERE clause เท่านั้น
ตัวอย่างเปรียบเทียบการดึงข้อมูลจาก data source โดยที่มี และไม่มี predicate pushdown
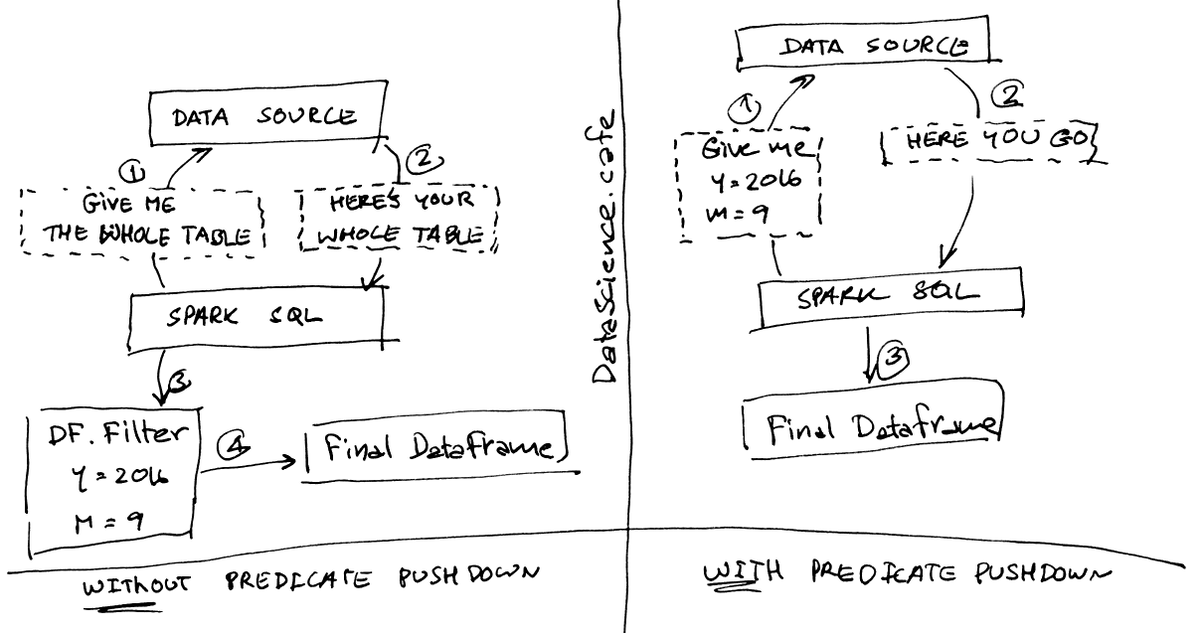
Without predicate pushdown
- Spark request dataset ทั้่งหมดจาก data source
- Data source ส่งข้อมูลทั้ง table มาให้ Spark
- Spark ทำการ filter ข้อมูล
- เก็บ output ไว้ใน dataframe
With predicate pushdown
- Spark request dataset จาก data source โดยส่ง filter ไปด้วย
- Data source ทำการ filter ข้อมูลตามที่ต้องการ และส่งผลกลับมาให้ Spark
- Spark เก็บ output ไว้ใน DataFrame
ตัวอย่างการทำ pushdown
spark.read.jdbc(mysqlUrl, targetTable, prop).where("year = 2016 and month = 9").explain
== Physical Plan ==
*Scan JDBCRelation(fuel_sales) [year#233,month#234,fuelType#235,retailer#236,province#237,volume#238,volume_int#239] PushedFilters: [EqualTo(year,2016), EqualTo(month,9)], ReadSchema: struct<year:int,month:int,fuelType:string,retailer:string,province:string,volume:string,volume_in...
ในกรณีที่ data source หรือ connector หรือ query ที่ต้องการใช้ ไม่รองรับการทำ pushdown
spark.read.jdbc(mysqlUrl, targetTable, prop).groupBy("year", "month", "retailer").agg(sum("volume_int")).explain
== Physical Plan ==
*HashAggregate(keys=[year#250, month#251, retailer#253], functions=[sum(cast(volume_int#256 as bigint))])
+- Exchange hashpartitioning(year#250, month#251, retailer#253, 200)
+- *HashAggregate(keys=[year#250, month#251, retailer#253], functions=[partial_sum(cast(volume_int#256 as bigint))])
+- *Scan JDBCRelation(fuel_sales) [year#250,month#251,retailer#253,volume_int#256] ReadSchema: struct<year:int,month:int,retailer:string,volume_int:int>
ถ้าหาก data source ไม่รองรับการทำ predicate pushdown เรายังสามารถส่ง raw query ไปยัง data source โดยตรงได้ด้วย เช่น
val arbitrarySql = "(SELECT * FROM fuel_sales WHERE year = 2016 AND month = 9) as tbl"
spark.read.jdbc(mysqlUrl, arbitrarySql, prop).explain
== Physical Plan ==
*Scan JDBCRelation((SELECT * FROM fuel_sales WHERE year = 2016 AND month = 9) as tbl) [year#635,month#636,fuelType#637,retailer#638,province#639,volume#640,volume_int#641] ReadSchema: struct<year:int,month:int,fuelType:string,retailer:string,province:string,volume:string,volume_in…
หรือ
val arbitrarySql = "(SELECT year, month, retailer, sum(volume_int) as sumVolume FROM fuel_sales GROUP BY year,month,retailer) as tbl"
spark.read.jdbc(mysqlUrl, arbitrarySql, prop).explain
== Physical Plan ==
*Scan JDBCRelation((SELECT year, month, retailer, sum(volume_int) as sumVolume FROM fuel_sales GROUP BY year,month,retailer) as tbl) [year#651,month#652,retailer#653,sumVolume#654] ReadSchema: struct<year:int,month:int,retailer:string,sumVolume:decimal(32,0)>
เป็นต้น
การทำ filter ที่ data source มักจะให้ performance ที่ดีกว่า ดังนั้นการเลือกใช้ data source หรือ connector ต่างๆ จึงควรที่จะนำความสามารถในการทำ pushdown มาพิจารณาด้วย
อย่างไรก็ตาม ไม่ว่าจะเป็นการทำ pushdown หรือการส่ง raw query ไม่ได้หมายความว่าเราจะได้ performance ที่ดีกว่าเสมอไป จึงควรเลือกใช้อย่างมีสติ และระมัดระวัง
ในตอนต่อไป เราจะมาดูกันว่า หาก data source มีการupdate ข้อมูล เราจะรับมือกับการ update ข้อมูลได้อย่างไรบ้าง
ย้อนกลับไปอ่าน ตอนที่ 1:data ingestion
This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License