Spark เพื่อ data warehouse offload (ตอนที่ 1:data ingestion)
จากบทความเกี่ยวกับ ทำไม column store ถึงมีความสำคัญกับงาน analytics? เมื่อเดือนกันยายนที่ผ่านมา ผู้เขียนได้เขียนถึงการทำ proof of concept บน SparkSQL + parquet file เพื่อแสดงให้เห็นว่าสามารถใช้การเก็บข้อมูลแบบ column store เพื่อช่วยให้ทำงาน analytics ได้เร็วกว่า และยังสามารถลด load บน RDBMS ได้อีกด้วย
ในซีรีส์ Spark เพื่อ data warehouse offload นี้ ผู้เขียนจะแนะนำตัวอย่างการนำ Spark มาทำ RDBMS / data warehouse offload เพื่อช่วยให้องค์กรประหยัดเงิน และประหยัดเวลาในการจัดการกับข้อมูล ไม่ว่าจะเป็นข้อมูลที่ Big หรืิอไม่ Big ก็ตาม
Spark SQL ไม่ใช่ RDBMS แต่เป็น distributed query engine ที่สามารถช่วยให้ผู้ใช้เขียน SQL เพื่อ query บนชุดข้อมูลขนาดใหญ่ได้โดยไม่ต้องเขียนโปรแกรม
Spark SQL สามารถ ดึงข้อมูลจาก data source ที่หลากหลาย ไม่ว่าจะเป็น CSV, JSON, JDBC, หรือ connector พิเศษของ vendor ที่สร้างขึ้นมาสำหรับ Spark โดยเฉพาะ เช่น Netezza
(ตัวอย่างการเชื่อมต่อ Spark เข้ากับ mysql)
// importing data from RDBMS into DataFrame
val mysqlUrl = "jdbc:mysql://localhost:3306/student"
val targetTable = "fuel_sales"
val mysqlUser = "student"
val mysqlPass = "password"
val prop = new java.util.Properties
prop.setProperty("user", mysqlUser)
prop.setProperty("password", mysqlPass)
prop.setProperty("driver", "com.mysql.jdbc.Driver")
val fuelSales = spark.read.jdbc(mysqlUrl, targetTable, prop)
fuelSales.createOrReplaceTempView("fuelSales")
fuelSales.printSchema
root
|-- year: integer (nullable = false)
|-- month: integer (nullable = false)
|-- fuelType: string (nullable = true)
|-- retailer: string (nullable = true)
|-- province: string (nullable = true)
|-- volume: string (nullable = true)
|-- volume_int: integer (nullable = true)
เมื่อเชื่อมต่อเสร็จแล้ว สามารถใช้ Spark SQL query ข้อมูลจาก mysql โดยตรงได้เลย
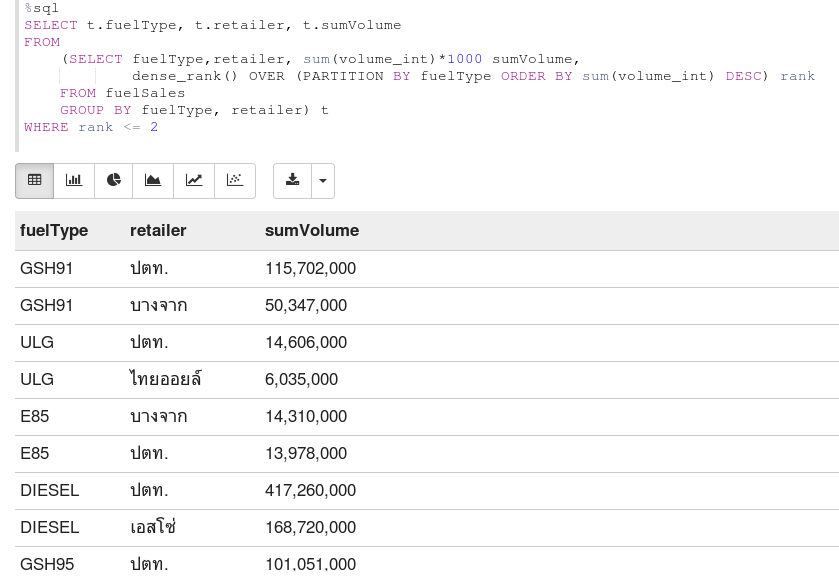
หรือจะทำการดึงข้อมูลจากทั้ง table มาเก็บเป็นไฟล์ parquet ก็ได้
fuelSales.write.format("parquet").saveAsTable("sparkFuelSalesTable")
spark.sql("select count(1) from sparkFuelSalesTable").show
+--------+
|count(1)|
+--------+
| 6391|
+--------+
Parquet เป็น column-store format ที่นิยมใช้ในการเก็บข้อมูลของ Spark ที่มีประสิทธิภาพ และเหมาะกับงาน analytics Spark รองรับ file system หลายแบบเช่น local file system, HDFS, หรือ AWS S3
ในกรณีที่ table ต่างๆมีขนาดไม่ใหญ่มากนัก ก็สามารถเก็บไว้ใน local disk และใช้ single-node Spark ช่วยประมวลผลข้อมูลได้ โดยที่ไม่ต้องรบกวน RDBMS
หรือในกรณีที่มีข้อมูลใหญ่มาก ก็สามารถเก็บไว้ใน Hadoop (HDFS) หรือ S3 ได้ (ในกรณีที่ใช้ AWS)
ปกติแล้ว 1 query บน mysql คือ 1 thread ดังนั้นการ transfer ข้อมูลจาก RDBMS มาใน spark อาจจะไม่เร็วเท่าที่ควร วิธีหนึ่งที่ Spark ใช้ช่วยในการดึงข้อมูลออกมาให้เร็วขึ้นโดยการแบ่ง table เป็นหลายๆ logical partition แล้วใช้หลายๆ JDBC sessions ช่วยกันอ่าน
ตัวอย่างเช่น..
val prop = new java.util.Properties
prop.setProperty("user", mysqlUser)
prop.setProperty("password", mysqlPass)
prop.setProperty("driver", "com.mysql.jdbc.Driver")
prop.setProperty("partitionColumn", "year")
prop.setProperty("lowerBound", "2010")
prop.setProperty("upperBound", "2016")
prop.setProperty("numPartitions", "7")
prop.setProperty("fetchsize", "100")
val fuelSales = spark.read.jdbc(mysqlUrl, targetTable, prop)
ตัวอย่างข้างบนสั่งให้ Spark partition table โดยใช้ column และ hint ให้ Spark รู้ว่า lower bound ของข้อมูลคือปี 2010 และ upper bound คือปี 2016 (row ที่ year < 2010 และ year > 2016 ก็จะถูกดึงมาด้วย)
เท่านี้เราก็สามารถดึงข้อมูลจาก RDBMS มาเก็บไว้ใน parquet file เพื่อใช้ Spark ในการประมวลผลทีหลังได้แล้ว
ใน blog post ต่อไปของซีรีส์นี้ เราจะมาดูกันว่าข้อจำกัดในการ ingest ข้อมูลเข้ามาเก็บไว้ใน parquet ไฟล์มีอย่างไรบ้าง และเราจะแก้ไขข้อจำกัดนี้อย่างไร
อ่านตอนต่อไป : ตอนที่ 2:incremental data load
This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License